def solution(s):
answer = []
s = sorted(s[2:-2].split("},{"), key=lambda x: len(x))
if len(s)==1:
return list(map(int, s))
for i in range(len(s)-1):
if i==0: answer.append(s[i])
answer.append(''.join(set(s[i+1].split(",")) - set(s[i].split(','))))
return list(map(int,answer))
코드 리뷰 후
def solution(s):
import re
from collections import Counter
return list(map(int, [i for i, v in sorted(Counter(re.findall('\d+',s)).items(), key=lambda x: x[1],reverse=True)]))
def solution(str1, str2):
import re
list1 = [(str1[i:i+2]).lower() for i in range(len(str1)-1) if re.match('[a-zA-Z]{2}',str1[i:i+2])]
list2 = [(str2[i:i+2]).lower() for i in range(len(str2)-1) if re.match('[a-zA-Z]{2}',str2[i:i+2])]
gyo = 0
if not list1 and not list2: return 65536
for i in list1:
if i in list2:
gyo+=1
list2[list2.index(i)] = '$$$'
hap = len(list1+list2)-gyo
return int((gyo/hap)*65536)
코드 리뷰 후
def solution(str1,str2):
import re
list1 = [(str1[i:i+2]).lower() for i in range(len(str1)-1) if re.match('[a-zA-Z]{2}',str1[i:i+2])]
list2 = [(str2[i:i+2]).lower() for i in range(len(str2)-1) if re.match('[a-zA-Z]{2}',str2[i:i+2])]
if not list1 and not list2: return 65536
gyo = set(list1) & set(list2)
hap = set(list1) | set(list2)
_gyo = sum([min(list1.count(g), list2.count(g)) for g in gyo])
_hap = sum([max(list1.count(h), list2.count(h)) for h in hap])
return int(_gyo/_hap*65536)
깨달은 점
정규식 좋다
다중집합은 원소의 중복을 허용한다.. 그래서 set()을 사용하지 않고 코딩을 했는데 다른 사람들이 푼 방법을 보니까 기가막힌다! 진짜 어떻게 저런 생각을 하지..
JdbcTemplate을 이용하여 구현체를 만들면 코드가 확~ 줄어든다. 반복 코드를 제거해주기 때문이다. 하지만 SQL 문은 직접 작성해줘야한다. ㅜ.ㅜ
쿼리문을 작성하여 db에서 데이터를 가져올 때는 jdbcTemplate.query()를 사용해서 RowMapper로 감싸준다음 가져올 수 있다.
jdbcTemplate.query(), RowMapper<Member>
insert를 위한 기능은 SimpleJdbcInsert()를 사용하면 된다. usingGenerateKeyColumns에는 pk 컬럼명을 넣어주면 된다. executeAndReturnKey는 쿼리문을 실행해서 레코드를 Map을 통해 만든 형식에 따라 가져와준다.
SimpleJdbcInsert()
JPA
객체를 테이블로 mapping 해주는 프레임 워크.
JPA는 인터페이스다. 그러므로 구현체가 필요한데 이러한 구현체에 Hibernate라는 것이 있고 이 강좌에서는 이를 사용한다.
JPA를 사용하면 JdbcTemplate을 사용할 때 불편했던 바로바로 sql문을 작성하지 않아도 된다. JPA가 기본적인 SQL을 직접 만들어서 실행시켜준다.
em.persist()
모든 쿼리문을 쓰지 않아도 가능한 것은 아니다. 위의 insert나 pk(기본키)를 기준으로 데이터를 찾는 기능은 구현되어있지만, 그 외의 기능은 직접 쿼리문을 JPQL로 짜줘야한다.
em.find() -> 기본키를 이용하여 데이터 찾기em.createQuery()
JPA는 통해 데이터를 변경하려면 트랜잭션 안에서 실행해야한다. 따라서 @Transactional 어노테이션을 service 클래스 위에 써준다.
@Transactional
JPA는 엔티티 매니저(EntityManager)로 모두 동작한다. build.gradle에 data-jpa를 가져오면 spring boot가 EntityManager를 생성하고 db랑 연결을 하고 이런 모든 동작을 해준다.
data-jpa
우리는 생성된 EntityManager를 가져와서 사용하면 된다. 여기서 @Autowired 안해줘도 가져올 수 있는 이유는 클래스에 생성자가 하나일때는 @Autowired안해도 알아서 해준다고 한다... 꿀팁~
Entitymanager, constructor
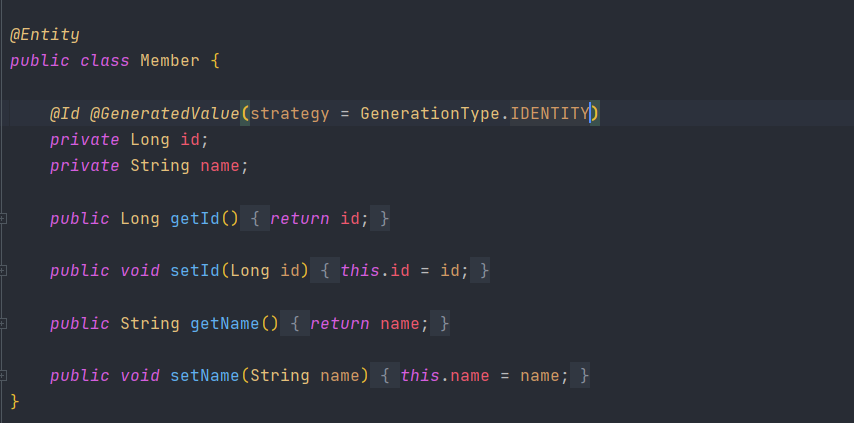
도메인 객체 위에 @Entity 어노테이션을 써서 mapping 시켜줘야 한다. 또한 pk를 알려주기 위해 @Id 라는 어노테이션도 써줘야하고, id는 시스템상에서 1씩 증가해서 db에 넣어주기 때문에(이를 IDENTITY 방식이라 함) GenerationType.IDENTITY도 추가해야한다.
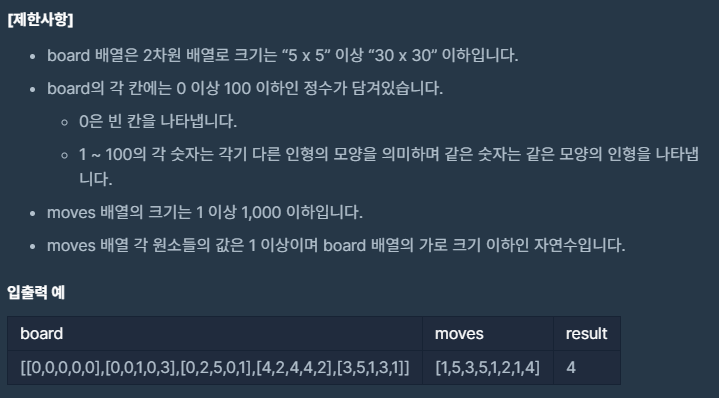
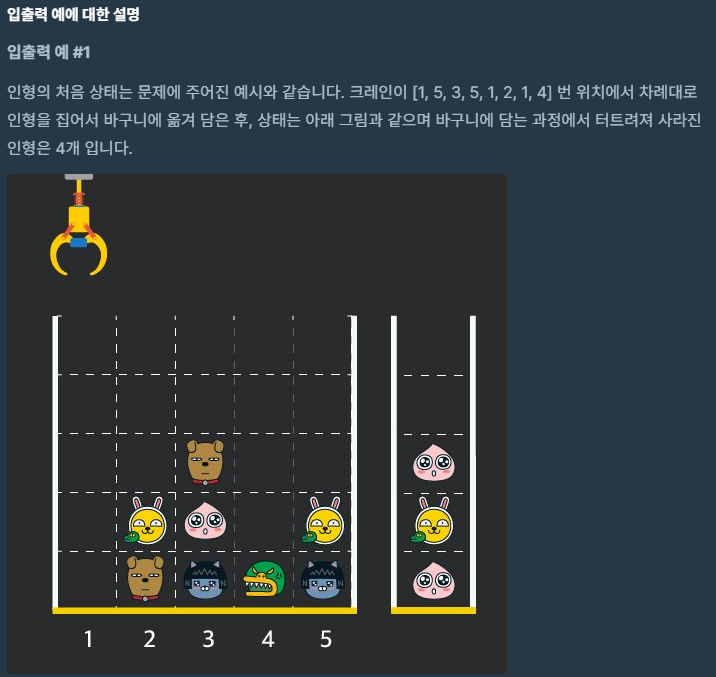
def solution(board, moves):
answer = 0
stack = []
for i in moves:
for j in board:
if j[i-1]!=0:
if len(stack)==0 or stack[-1]!=j[i-1]:
stack.append(j[i-1])
else:
stack.pop()
answer+=2
j[i-1]=0
break
return answer
우리가 아무렇지 않게 클래스 위에 @Controller 이런식으로 쓰는 어노테이션들은 이 클래스 객체를 컨테이너에 생성해서 넣어주고 컨테이너에서 관리하겠다는 뜻으로 쓰는 것이다.
이것을 스프링 컨테이너에서 스프링 빈이 관리된다고 표현한다.
스프링이 관리를 하게 되면 이제부터는 다~ 스프링 컨테이너에 등록하고 컨테이너로부터 받아서 써야한다.
즉, 컨테이너안에서 모든 것을 해결해야한다.
저번 시간까지 service와 repository를 만들었는데 이제 뷰를 사용자에게 보여주기 위해 controller를 만들어야한다.
Controller, Service, Repository는 정형화된 패턴이다.
Controller를 통해서 외부의 요청을 받고
Service에서 비즈니스 로직을 만들고
Repository에서 데이터를 저장한다.
여기서 보면 Controller는 요청을 받아서 Service를 통해 회원가입을 하고, 조회를 할 것이다. 이 때, 의존관계가 있다고 표현한다. 의존관계가 있으므로 Controller와 Service를 연결해야하고 이를 위해 생성자 위에 @Autowired라는 어노테이션을 쓰면 자동으로 연결해준다.
자동으로 연결해준다는 의미는 아래 예시 코드를 통해 보여주도록 하겠다.
package hello.helloSpring.controller;
import hello.helloSpring.service.MemberService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
@Controller
public class MemberController {
private final MemberService memberService;
@Autowired // 스프링이 뜰 때, 컨테이너에서 관리하는 memberService 객체와 연결해준다.
public MemberController(MemberService memberService) {
this.memberService = memberService;
}
}
스프링이 시작될 때, 스프링은 @Controller를 보고 MemberController가 컨트롤러 역할이구나 라고 생각하고 객체를 생성하여 컨테이너에 넣는다. (==빈을 생성한다.)
이 때, Controller는 Service를 통해 기능을 수행하므로 연관 관계가 있다. 이를 위해 @Autowired를 생성자 위에 써주면 이 Controller 객체를 생성할 때 생성자를 통해 컨테이너에 존재하는 MemberService를 넣어주면서 빈이 생성되는 것이다.
한 마디로 말하자면, 스프링은 @Controller를 보고 Controller 객체를 생성하고 그 때 생성자를 호출하면서 스프링 컨테이너에 있던 MemberService를 가져다가 넣어주는 것이다. 이해 완료?!!?
여기서 주의할 점은 저번 시간에 한 코드에서 위의 코드를 추가한다면 에러가 난다.
에러
왜냐하면 이전 코드의 MemberService 클래스는 컨테이너에 빈으로 등록되지 않았기 때문이다. (어노테이션 안썼음)
따라서 MemberService 클래스 위에 @Service라는 어노테이션을, 똑같은 방식으로 MemoryMemberRepository 클래스 위에 @Repository로 어노테이션을 쓰면 스프링이 시작될 때 컨테이너에 넣어서 관리가 된다.
위와 같은 @Controller, @Service, @Repository 를 컴포넌트 스캔이라고 하며
@Autowired를 자동 의존관계 설정이라고 한다.
자바 코드로 직접 스프링 빈 등록하기
어노테이션을 쓰지 않고 직접 코드로 등록하기 위해 @Controller를 제외한 @Service, @Repository, @Autowired를 다 지우고 시작한다.
1. hello.helloSpring 밑에 SpringConfig 클래스를 만들어준다.
구조
2. 코드를 작성해준다.
package hello.helloSpring;
import hello.helloSpring.repository.MemberRepository;
import hello.helloSpring.repository.MemoryMemberRepository;
import hello.helloSpring.service.MemberService;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SpringConfig {
@Bean
public MemberService memberService(){
return new MemberService(memberRepository());
}
@Bean
public MemberRepository memberRepository(){
return new MemoryMemberRepository();
}
}
@Configuration을 통해 스프링에게 알리고 @Bean을 통해 빈을 등록하겠다고 하면 된다.
MemberService를 생성할때는 memberRepository가 필요한데(연관 관계) 이때 memberRepository()를 호출해주면 된다.
직접 코드를 작성하는 것의 장점은
현재 어떤 db를 사용할 것인지 정해져있지 않은 상황이라고 가정이 되어있다. 나중에 db가 결정되면 저 Repository만 바꿔주면 되는 것이다. 즉, 다른 코드 손 볼 필요 없이 return new dbMemberRepository()와 같은 다른 레포지토리를 생성해주면 된다.
def solution(n, computers):
answer = 0
visited = []
stack = [0]
all_stack = set([i for i in range(n)])
while True:
if len(visited)==n:
return answer+1
if len(stack)==0:
answer+=1
stack.append(list(all_stack-set(visited))[0])
a = stack.pop()
if a not in visited:
visited.append(a)
for j in range(n):
if computers[a][j]==1 and a!=j and j not in visited:
stack.append(j)
탈출조건: 모든 노드를 다 방문했을 때
len(stack)이면 네트워크가 끊긴거라 answer+=1 하고 visited 안한 노드를 stack에 넣고 그 노드가 속해있는 네트워크를 다시 돈다.
네트워크가 끊기면 다음 방문할 노드를 어떻게 정할까 고민했었는데 set을 이용해서 all_stack에서 지금까지 방문한 노드의 리스트를 빼고 그 중 가장 앞에 있는 노드로 정했다. list는 빼기가 안되는데 set은 된다. set은 인덱스로 접근이 안되서 다시 list()로 변환하고 인덱스 접근을 시도해야한다.