스프링 JdbcTemplate
- JdbcTemplate을 이용하여 구현체를 만들면 코드가 확~ 줄어든다. 반복 코드를 제거해주기 때문이다. 하지만 SQL 문은 직접 작성해줘야한다. ㅜ.ㅜ
- 쿼리문을 작성하여 db에서 데이터를 가져올 때는 jdbcTemplate.query()를 사용해서 RowMapper로 감싸준다음 가져올 수 있다.

- insert를 위한 기능은 SimpleJdbcInsert()를 사용하면 된다. usingGenerateKeyColumns에는 pk 컬럼명을 넣어주면 된다. executeAndReturnKey는 쿼리문을 실행해서 레코드를 Map을 통해 만든 형식에 따라 가져와준다.

JPA
- 객체를 테이블로 mapping 해주는 프레임 워크.
- JPA는 인터페이스다. 그러므로 구현체가 필요한데 이러한 구현체에 Hibernate라는 것이 있고 이 강좌에서는 이를 사용한다.
- JPA를 사용하면 JdbcTemplate을 사용할 때 불편했던 바로바로 sql문을 작성하지 않아도 된다. JPA가 기본적인 SQL을 직접 만들어서 실행시켜준다.

- 모든 쿼리문을 쓰지 않아도 가능한 것은 아니다. 위의 insert나 pk(기본키)를 기준으로 데이터를 찾는 기능은 구현되어있지만, 그 외의 기능은 직접 쿼리문을 JPQL로 짜줘야한다.


- JPA는 통해 데이터를 변경하려면 트랜잭션 안에서 실행해야한다. 따라서 @Transactional 어노테이션을 service 클래스 위에 써준다.

- JPA는 엔티티 매니저(EntityManager)로 모두 동작한다. build.gradle에 data-jpa를 가져오면 spring boot가 EntityManager를 생성하고 db랑 연결을 하고 이런 모든 동작을 해준다.

- 우리는 생성된 EntityManager를 가져와서 사용하면 된다. 여기서 @Autowired 안해줘도 가져올 수 있는 이유는 클래스에 생성자가 하나일때는 @Autowired안해도 알아서 해준다고 한다... 꿀팁~

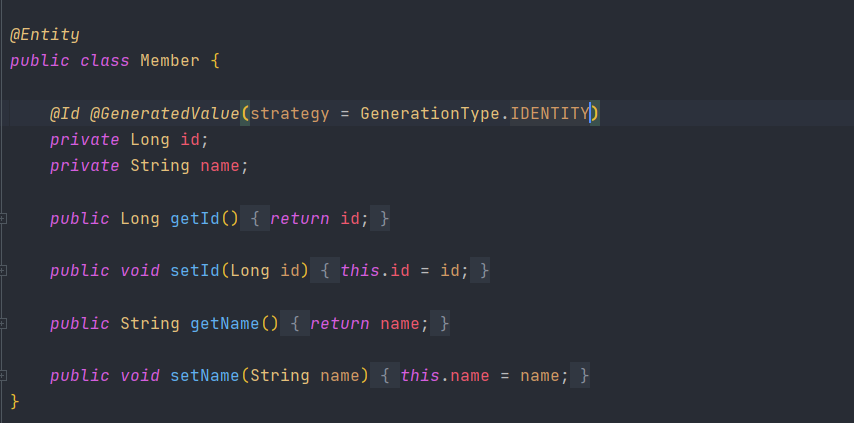
- 도메인 객체 위에 @Entity 어노테이션을 써서 mapping 시켜줘야 한다. 또한 pk를 알려주기 위해 @Id 라는 어노테이션도 써줘야하고, id는 시스템상에서 1씩 증가해서 db에 넣어주기 때문에(이를 IDENTITY 방식이라 함) GenerationType.IDENTITY도 추가해야한다.
- JPA를 사용하면, SQL과 데이터 중심의 설계에서 객체 중심의 설계로 패러다임을 전환할 수 있다. -> 개발 생산성 크게 향상
스프링 데이터 JPA
- 스프링 데이터 JPA는 인터페이스다. 구현체를 구현해야 사용할 수 있지만 얘는 뭔가 다르다. 필요없다.. 즉 구현체 없이 인터페이스 클래스 하나로 사용이 가능하다는 것이다.
- 스프링 데이터 JPA가 자동적으로 스프링 빈에 등록해준다.
- 사용법은 JpaRepository(인터페이스)를 extends(상속) 해주면 된다. jpaRepository<T, ID> 형식으로 써주면 된다. T는 테이블(?), ID는 PK(기본키) 데이터 자료형을 써주면 된다.

- JpaRepository를 타고 가보면 구현하려던 메쏘드들이 이미 구현이 되어있다~


깨달은 점
스프링 데이터 JPA 짱이다..
'Backend > Spring' 카테고리의 다른 글
| [IntelliJ] custom template 생성하기 (0) | 2021.01.14 |
|---|---|
| [인프런 스프링 입문] AOP (0) | 2021.01.10 |
| [인프런 스프링 입문] 회원 관리 예제 - 웹 MVC 개발 (0) | 2021.01.07 |
| [인프런 스프링 입문] 스프링 빈과 의존관계 (0) | 2021.01.07 |
| [인프런 스프링 입문] 회원 관리 예제 - 백엔드 개발 (0) | 2021.01.06 |