이번 글에서는 블록 암호에 이어서 스트림 암호를 공부해보도록 하겠습니다!!
스트림 암호는 블록 암호보다 취약하고 더 자주 깨졌다는 이유로 꺼리는 사람들이 있었는데요 지금은 다행히 안전한 스트림 암호를 설계하는 방법이 알려져 있고, 블루투스 연결, 이동전화의 4G 통신, TLS 연결 등이 스트림 암호 덕분에 안전하게 보호된다고 합니다!
5.1 스트림 암호의 작동 방식
스트림 암호는 DRBG( 결정론적 난수 비트 발생기 )처럼 결정론적이다. 스트림 암호와 DRBG의 차이는 DRBG는 하나의 값을 입력받지만 스트림 암호는 두 개의 값( 키, 논스(nonce) )을 입력받는다.
키는 반드시 비밀, 논스는 비밀일 필요는 없다.

스트림 암호의 암호화 방식
암호화 방식을 살펴 보면, 키와 논스를 입력 받아 스트림 암호 알고리즘을 통해 키스트림(KS)을 생성한다. 키스트림과 평문 P를 XOR 하면 암호문이 나오고, 그 암호문을 다시 키스트림과 XOR 하면 평문이 나온다.
스트림 암호에서 키와 논스는 각각 재사용이 가능하지만 같이 재사용을 하면 이전과 동일한 KS가 생성되므로 동시에 재사용은 하면 안된다.
5.1.1 상태 있는 스트림 암호와 카운터 기반 스트림 암호
크게 봤을 때, 스트림 암호는 상태 있는 스트림 암호(stateful stream cipher)와 카운터 기반 스트림 암호(counter-based stream cipher)로 나뉜다.
i ) 상태 있는 스트림 암호 ex) RC4

주어진 키와 논스로 상태를 초기화(init) 한 후 갱신 함수(update)를 통해서 상태값을 갱신하고, 상태로 부터 하나 이상의 키 스트림 비트들을 생성하고 평문과 XOR 해서 암호문을 얻는다.
ii ) 카운터 기반 스트림 암호
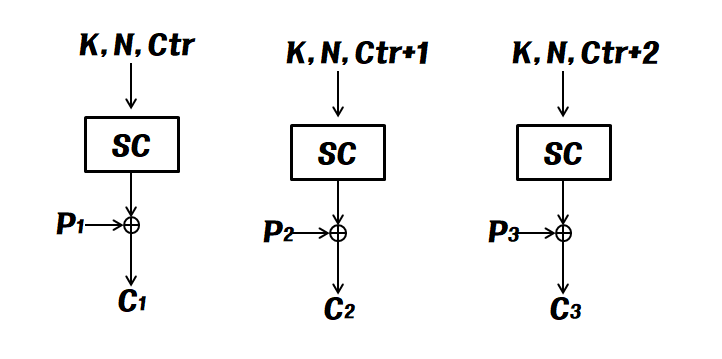
키와 논스, 카운터 값을 이용해서 키스트림 조각들을 생성한다.
스트림 암호의 내부는 대상 플랫폼에 따라 크게 두 범주로 나뉜다. 하나는 하드웨어 지향적 스트림 암호, 다른 하나는 소프트웨어 지향적 스트림 암호이다.
5.2 하드웨어 지향적 스트림 암호
암호의 하드웨어 구현은 암복호화 이외의 용도로는 쓰이지 않는다.
초창기 스트림 암호들은 복잡한 워드 단위 연산을 피하기 위해 비트들을 다루었기 때문에 하드웨어에서 더 효율적이었다. 또한 블록 암호보다 구현 비용이 낮아서 잘 쓰였었는 데 현재는 블록 암호가 스트림 암호보다 비싸지 않다. 그렇긴 하지만, 예전에 하드웨어에 대해 최고의 선택이었다는 이유로 지금도 스트림 암호를 하드웨어와 연관 시키는 경우가 많다.
5.2.1 FSR(되먹임 자리이동 레지스터)
되먹임 함수를 f 라고 하고 FSR의 각 갱신 연산에서는 그 상태의 값을 변경하고 하나의 출력 비트를 산출한다.
식으로 나타내보자면
Rt+1 = (Rt << 1) | f(Rt)
여기서 | 는 OR 이고 << 는 왼쪽으로 shift 이다.
ex) 되먹임 함수 f는 주어진 네 비트를 XOR로 결합하는 함수, 초기 상태 : 1 1 0 0
f(1100) = 1 xor 1 xor 0 xor 0 = 0
새로운 상태 : (1100<<1) | 0 = 1000
이런 식으로 계속해나가면
1100 -> 1000 -> 0001 -> 0011-> 0110 -> 1100 이렇게 되어서 주기(period)가 5가 된다.
보안을 위해서는 이러한 반복 패턴을 피해야 하며 주기가 길어야 한다.
i ) LFSR(선형 되먹임 자리이동 레지스터)
되먹임 함수가 선형 함수인 FSR이다.
암호학에서 선형성은 예측가능성과 같은 말이다. 바탕에 깔린 수학 구조가 단순함.
LFSR의 주기는 되먹임 함수가 레지스터의 어떤 비트들을 XOR하느냐에 크게 의존. -> 최대 주기인 2^n-1이 나오도록 비트들을 선택하는 방법이 알려져 있음.
만약 1번째, 3번째, 4번째 비트들을 xor 한다고 하면 다항식을 1+X^1+X^3+X^4 로 만들 수 있고 이렇게 만든 다항식이 원시다항식(기약다항식, 즉 더 이상 인수분해할 수 없는 다항식)이면 FSR의 주기가 최대가 된다.
1+X^1+X^3+X^4 = (1+X)(1+X^3) 이므로 원시다항식이 아님.
벌러캠프-매시 알고리즘(Berlekamp-Massey algorithm) 이용해서 LFSR의 수학 구조로 정의된 방정식들을 풀 수 있어서 LFSR은 안전하지 않다.
ii ) 필터링된 LFSR

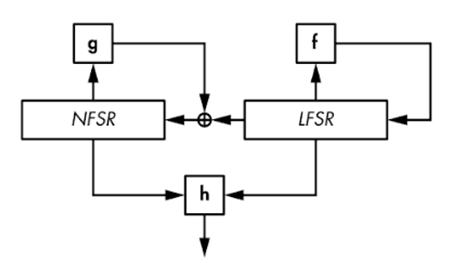
LFSR이 출력한 비트들을 비선형함수로 변환한다면 LFSR의 선형성을 숨길 수 있고, 비보안성을 완화시킬 수 있을 것이다. 이러한 LFSR을 필터링된 LFSR이라고 부른다.
그림에서 g 함수는 반드시 비선형 함수여야 한다. -> XOR 뿐만 아니라 AND, OR 연산으로도 결합
하지만 아래의 공격을 이용하면 이 암호체계를 깰 수 있다.
1) 대수적 공격(algebraic attack) : 출력 비트들로부터 비선형 방정식들을 연역해서 푼다.
2) 큐브 공격(cube attack) : 비선형 방정식들의 도함수를 계산해서 방정식들의 차수를 1까지 끌어내린다.
3) 고속 상관 공격(fast correlation attack) : 비선형성을 가지고 있긴 하지만 선형함수처럼 행동하는 경향이 있는 필터링 함수들을 활용한다.
iii ) NFSR(비선형 FSR)
LFSR과 비슷하지만 되먹임 함수가 비선형이다.
장점 : 암호학적으로 강해진다
단점 : NFSR의 주기를 효율적으로 알아내는 것이 불가능하다.
주기가 짧으면 LFSR과 NFSR을 결합해서 최대 주기를 보장하고 암호학적 강도도 보장해서 사용 -> Grain-128a
5.2.2 Grain-128a
Grain-128a는 128비트 키와 96비트 논스를 사용한다.
128비트 키는 NFSR의 128비트 레지스터에 복사, 96비트 논스의 비트들은 LFSR 레지스터의 앞부분 96비트에 복사하고 나머지 32 비트 중 31개의 비트에는 1로 마지막 비트는 0으로 설정한다. 초기화 단계에서는 시스템 전체를 256번 갱신하고 그 다음에야 첫 번째 키스트림 비트를 출력한다.
<LFSR의 되먹임 함수>
f(L) = L32 + L47 + L58 + L90 + L121 + L128
<NFSR의 되먹임 함수>
g(N) = N32 + N37 + N72 + N102 + N128 + N44N60 + N61N125 + N63N67 + N69N101 + N80N88 + N110N111 + N115N117 + N46N50N58 + N103N104N106 + N33N35N36N40
필터 함수 h 역시 비선형함수이다. 이 함수는 NFSR에서 비트 9개, LFSR에서 비트 7개를 받아서 적절히 결합한다.
h(x) = bi+12 Si+8 + Si+13Si+20 + bi+95Si+42 + Si+60Si+79 + bi+12bi+95Si+94
5.2.3 A5/1
A5/1은 2G 이동통신 표준에서 음성 통신을 암호화하는 데 쓰였던 스트림 암호이다.
- A5/1의 작동 방식
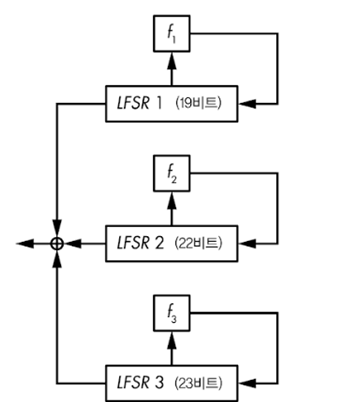
그림에서 보듯이 A5/1은 비트 수가 각각 19, 22, 23인 LFSR들을 사용한다.
< 되먹임 다항식 >
LFSR 1 = 1 + X^14 + X^17 + X^18 + X^19
LFSR 2 = 1 + X^21 + X^22
LFSR 3 = 1 + X^8 + X^21 + X^22 + X^23
< 갱신 매커니즘 >
1. LFSR 1의 비트 9의 값, LFSR 2의 비트 11의 값, LFSR 3의 비트 11의 값이 모두 같거나 한 비트만 다르다. 이 비트들을 클로킹 비트 ( clocking bit ) 라고 한다.
2. 만약 클로킹 비트가 1 1 1 이면 1의 클로킹 비트를 가지고 있는 레지스터끼리 xor을 하고 1 0 0 이면 0이 더 많으니까 0의 클로킹 비트를 가지고 있는 레지스터끼리 xor을 한다.
- A5/1에 대한 공격 기법
1. 정교한 공격 ( subtle attack ) : 내부 선형성, 단순한 불규칙 클로킹 체계를 활용
- 추측 후 판정 ( guess-and-determine )이라고 부르는 한 정교한 공격 기법에서 공격자는 상태의 특정 비밀 값들을 추측해서 다른 비밀 값들을 알아낸다.
↓ 이러한 공격을 나타낸 의사코드다.
LFSR 1의 초기 상태의 모든 가능한 2^19가지 값에 대해: LFSR 2의 초기 상태의 모든 가능한 2^22가지 값에 대해: 처음 11 클록 동안 LFSR 3의 클로킹 비트의 모든 가능한 2^11가지 값에 대해: LFSR 3의 초기 상태를 재구축한다. 추측이 맞는지 점검한다. 맞으면 반환하고 아니면 반복한다.
LFSR 1의 초기 상태의 모든 가능한 2^19가지 값에 대해:
LFSR 2의 초기 상태의 모든 가능한 2^22가지 값에 대해:
처음 11 클록 동안 LFSR 3의 클로킹 비트의 모든 가능한 2^11가지 값에 대해:
LFSR 3의 초기 상태를 재구축한다.
추측이 맞는지 점검한다. 맞으면 반환하고 아니면 반복한다.
2. 무차별 공격 ( brutal attack ) : 짧은 키와 프레임 번호 주입의 가역성 활용
- 코드북 공격을 함. -> 실제로 2G 이동통신의 암호문을 코드북 공격을 이용해서 거의 실시간으로 복호화할 수 있었다.
5.3 소프트웨어 지향적 스트림 암호
현대적인 CPU는 비트에 대한 연산에 걸리는 시간과 워드에 대한 연산에 걸리는 시간이 다를 바가 없기 때문에 바이트나 워드를 다루는 것이 더 효율적이다. 그래서 소프트웨어 스트림 암호가 하드웨어 암호보다 더 낫다. 현재 암호학자들이 가장 주목하는 설계 두 가지는 RC4와 Salsa20이다.
5.3.1 RC4
오랫동안 가장 널리 쓰인 스트림 암호인 RC4는 역공학을 통해 취약점이 노출되었다.
최초의 Wi-Fi 암호화 표준인 WEP ( Wired Equivalent Privacy; 유선 동등 프라이버시 ) 와 HTTPS 연결에 쓰이는 TLS ( Transport Layer Security; 전송 계층 보안 ) 프로토콜에 사용됐다.
- RC4의 작동 방식
RC4의 내부 상태인 256개의 바이트로 이루어진 배열 S를 키 K를 이용해서 초기화한다. -> 키 스케줄링 알고리즘
S의 두 인덱스를 선택해서 swap 하고 두 특정 바이트를 통해 키스트림을 생성한다. 여기서 얻은 키스트림을 평문 P와 XOR 하여 암호문을 얻는다.
j=0
S = range(256)
for i in range(256):
j = (j + S[i] + K[i%n]) % 256
S[i], S[j] = S[j], S[i]i = 0
j = 0
for b in range(m):
i = (i + 1) % 256
j = (j + S[i]) % 256
S[i], S[j] = S[j], S[i]
KS[b] = S[(S[i] + S[j]) % 256]위의 코드에서 m은 평문의 길이이고 그 길이 만큼 swap을 진행한다. 이 방식을 테이블 셔플링(shuffling) 방식이라고 한다.
- WEP의 RC4
: 무선망으로 자료를 전송하는 데이터그램인 802.11 프레임 안에 있는 페이로드 자료를 암호화한다. 한 세션에서 전송되는 모든 페이로드 자료는 40, 104 비트 길이의 동일한 비밀 키 사용. 각 페이로드 헤더에는 3 바이트 논스 값이 부호화되어있다.
여기서 문제!! RC4는 논스를 지원하지 않는다. -> WEP 설계자들은 무선 프레임 헤더에 24비트 논스를 포함하고 그것을 RC4의 비밀 키로 쓰이는 WEP 키의 앞에 붙였다.
* WEP의 논스 편법의 진정한 문제점
1. 논스가 너무 작다.
2. 논스와 키를 연결하는 방식 때문에 키를 복원하기 쉽다.
- TLS의 RC4
: TLS는 인터넷에서 쓰이는 가장 중요한 보안 프로토콜이다. HTTPS 연결의 용도로 널리 알려져 있지만 그 뿐아니라 VPN이나 이메일 서버, 이동통신 응용 프로그램 등의 여러 응용을 보호하는 데에도 쓰인다.
TLS의 약점은 전적으로 RC4 때문이다. -> 통계적 편향, 비무작위성
5.3.2 Salsa20

Salsa20은 현대적인 CPU에 최적화된 간단한 소프트웨어 지향적 스트림 암호이다.
Salsa20은 하나의 키 K와 하나의 논스 N, 카운터 값 Ctr로 이루어진 512 비트 블록을 핵심(core) 알고리즘을 이용해서 변환하고 그 결과를 원래 512비트 블록과 더해서 하나의 키스트림 블록을 산출한다.
- 쿼터 라운드 함수
이 함수는 네 개의 32비트 워드(a,b,c,d)를 다음과 같이 변환
b = b xor [(a + d) <<< 7]
c = c xor [(b + a) <<< 9]
d = d xor [(c + b) <<< 13]
a = a xor [(d + c) <<< 18]
- Salsa20의 512비트 상태의 변환

Salsa20 초기 상태
C0~C3 : 상수
K0~K7 : 키
V0, V1 : 논스
T0, T1 : 카운터
<변환 과정>
1. 열 라운드(column-round) - 홀수번째 라운드
2. 행 라운드(row-round) - 짝수번째 라운드
열 라운드와 행 라운드의 조합을 이중 라운드(double-round) -> salsa20은 이중 라운드를 10번 반복(2x10 = 20)
- Salsa20의 평가 : 10라운드 반복 후 무작위해 보이지만 그 자체가 보안성을 보장하지는 않는다.
하지만 RC4보다는 훨씬 안전하며, 통계적 편향이 없다.
- 차분 암호해독 : 상태들의 실제 값 자체가 아니라 상태들의 차이를 연구하는 차분 암호해독(differential cryptanalysis)
차분 암호해독으로 살펴본 결과 비트 하나 차이가 512 비트 상태의 거의 모든 비트로 전파되는 걸 확인할 수 있는 데 이 성질을 전확산(full diffusion)이라고 부른다.
상태의 진화가 XOR와 덧셈, 순환 자리 이동의 조합으로 이루어진 고도로 비선형적인 관계식이면 공격자가 미래의 상태 차이를 예측하기 어려워진다.
- Salsa20/8에 대한 공격
Salsa20/8은 라운드를 8회만 수행하는 버전으로 2^256회 미만의 연산으로 키를 복원하는 공격 기법이다.
통계적 편향을 활용하며 논스 N, 카운터 Ctr, 키 K를 알면 키스트림 계산을 거꾸로 수행해서 초기 상태를 복원할 수 있다.
키의 일부를 제대로 추측 -> 편향된 비트가 나타남 ( 편향된 비트가 나타났다? 추측한 키가 맞다 )
실제 공격시, 추측이 옳은지 판정하려면 키의 비트 220개가 필요하며 키스트림 블록들의 쌍 2^31개가 필요.
정확한 비트 220개를 알아낸 후에 나머지 비트 36 개는 무차별 대입 공격으로 알아내면 된다.

5.4 문제 발생 요인들
5.4.1 논스 재사용
: 같은 키에 대해 하나의 논스를 두 번 이상 재사용하는 바보!!
* SIV 모드 : 같은 논스를 두 번 사용해도 안전
5.4.2 잘못된 RC4 구현
: RC4의 알고리즘에는 swap이 사용된다. 그 때의 코드는
buf = S[i]
S[i] = S[j]
S[j] = buf이 때 buf라는 새로운 변수를 사용해야하는데 프로그래머들이 이를 피하기 위해 xor-swap 을 이용하여 코드를 짠다. 아래의 코드는 오류가 있는 코드의 일부이다.
#define SWAP(x,y) do {x^=y; y^=x; x^=y;} while(0)
...
SWAP(S[i], S[j]);이렇게 되어 있는 데 i=j 일때 문제가 생긴다.
xor swap에서 i=j이면 s[i]에 0이 배정된다. ( i와 j가 같아서 S[i]와 S[j]도 같음) -> 결국 모든 바이트가 0,,,,
이로써 스트림 암호도 알아봐버렸다!! 너무 어렵디만 하다보면 익숙해지겠지,, *^^*
더 열심히 해보자!! 바-위~
'Cryptography > 처음 배우는 암호화' 카테고리의 다른 글
| [암호스터디 #6] 해시 함수 (0) | 2020.04.26 |
|---|---|
| [암호 스터디 #4] 블록 암호 (1) | 2020.04.05 |
| [암호 스터디 #3] 암호학적 보안 (0) | 2019.12.03 |
| [암호 스터디 #2] 무작위성 (0) | 2019.09.27 |
| [암호 스터디 #1] 암호화 (1) | 2019.09.27 |