모두가 아는 나뭇잎 책을 보며 윈도우 구조체와 의미있는 멤버들을 뽑아서 출력하도록 하였다.
( 저는 개념을 익히기 위해 먼저 32bit pe 파일을 기준으로 코딩하였습니다. )
pe파일을 헥스에디터로 열었을 때 제일 먼저 보이는 구조체는 "_IMAGE_DOS_HEADER"이다.
typedef struct _IMAGE_DOS_HEADER { // DOS .EXE header
WORD e_magic; // Magic number
WORD e_cblp; // Bytes on last page of file
WORD e_cp; // Pages in file
WORD e_crlc; // Relocations
WORD e_cparhdr; // Size of header in paragraphs
WORD e_minalloc; // Minimum extra paragraphs needed
WORD e_maxalloc; // Maximum extra paragraphs needed
WORD e_ss; // Initial (relative) SS value
WORD e_sp; // Initial SP value
WORD e_csum; // Checksum
WORD e_ip; // Initial IP value
WORD e_cs; // Initial (relative) CS value
WORD e_lfarlc; // File address of relocation table
WORD e_ovno; // Overlay number
WORD e_res[4]; // Reserved words
WORD e_oemid; // OEM identifier (for e_oeminfo)
WORD e_oeminfo; // OEM information; e_oemid specific
WORD e_res2[10]; // Reserved words
LONG e_lfanew; // File address of new exe header
} IMAGE_DOS_HEADER, *PIMAGE_DOS_HEADER;
010 editor로 본 구조체 모습
< 주요 멤버 >
e_magic: 항상 "MZ" (0x5a4d)
e_lfanew: file에서의 nt header 시작 offset을 가리킨다.
DOS HEADER 출력 모습
그 다음 알아볼 구조체는 "_IMAGE_NT_HEADER" 이다. 이 구조체 안에 2개의 구조체가 더 있다. 함께 알아보도록 하자.
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
nt header안의 file header 모습
< 주요 멤버 >
Machine: 0x14C(32bit라서) , 0x8664(64bit)
NumberOfSections: section의 갯수를 말한다.( .text, .data, .rsrc 가 있다면 0x3 )
SizeOfOptionalHeader: 뒤에 올 _IMAGE_OPTIONAL_HEADER의 크기를 말한다.
Characteristics: File의 성격을 알려준다.
//Characteristic
#define IMAGE_FILE_RELOCS_STRIPPED 0x0001 // Relocation info stripped from file.
#define IMAGE_FILE_EXECUTABLE_IMAGE 0x0002 // File is executable (i.e. no unresolved external references).
#define IMAGE_FILE_LINE_NUMS_STRIPPED 0x0004 // Line nunbers stripped from file.
#define IMAGE_FILE_LOCAL_SYMS_STRIPPED 0x0008 // Local symbols stripped from file.
#define IMAGE_FILE_AGGRESIVE_WS_TRIM 0x0010 // Aggressively trim working set
#define IMAGE_FILE_LARGE_ADDRESS_AWARE 0x0020 // App can handle >2gb addresses
#define IMAGE_FILE_BYTES_REVERSED_LO 0x0080 // Bytes of machine word are reversed.
#define IMAGE_FILE_32BIT_MACHINE 0x0100 // 32 bit word machine.
#define IMAGE_FILE_DEBUG_STRIPPED 0x0200 // Debugging info stripped from file in .DBG file
#define IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP 0x0400 // If Image is on removable media, copy and run from the swap file.
#define IMAGE_FILE_NET_RUN_FROM_SWAP 0x0800 // If Image is on Net, copy and run from the swap file.
#define IMAGE_FILE_SYSTEM 0x1000 // System File.
#define IMAGE_FILE_DLL 0x2000 // File is a DLL.
#define IMAGE_FILE_UP_SYSTEM_ONLY 0x4000 // File should only be run on a UP machine
#define IMAGE_FILE_BYTES_REVERSED_HI 0x8000 // Bytes of machine word are reversed.
OR 연산으로 이루어지는데 위의 사진을 예로 들자면 0x10f라면 0x1 | 0x2 | 0x4 | 0x8 | 0x100 이겠죠? 그 뜻은 위에 주석처리된 부분을 참고하세요~
Characteristics: 섹션의 성격 ( 마찬가지로 or 연산 , 되게 많은 관계로 생략,,, )
Section Header 출력 모습
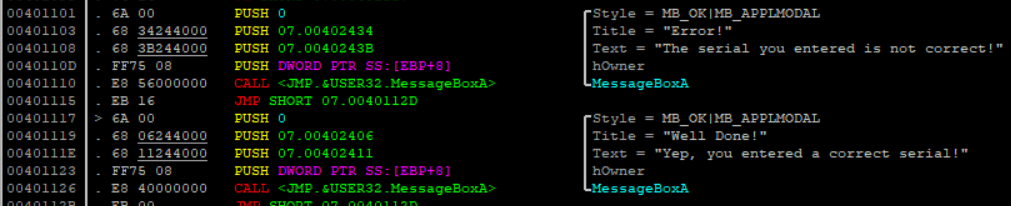
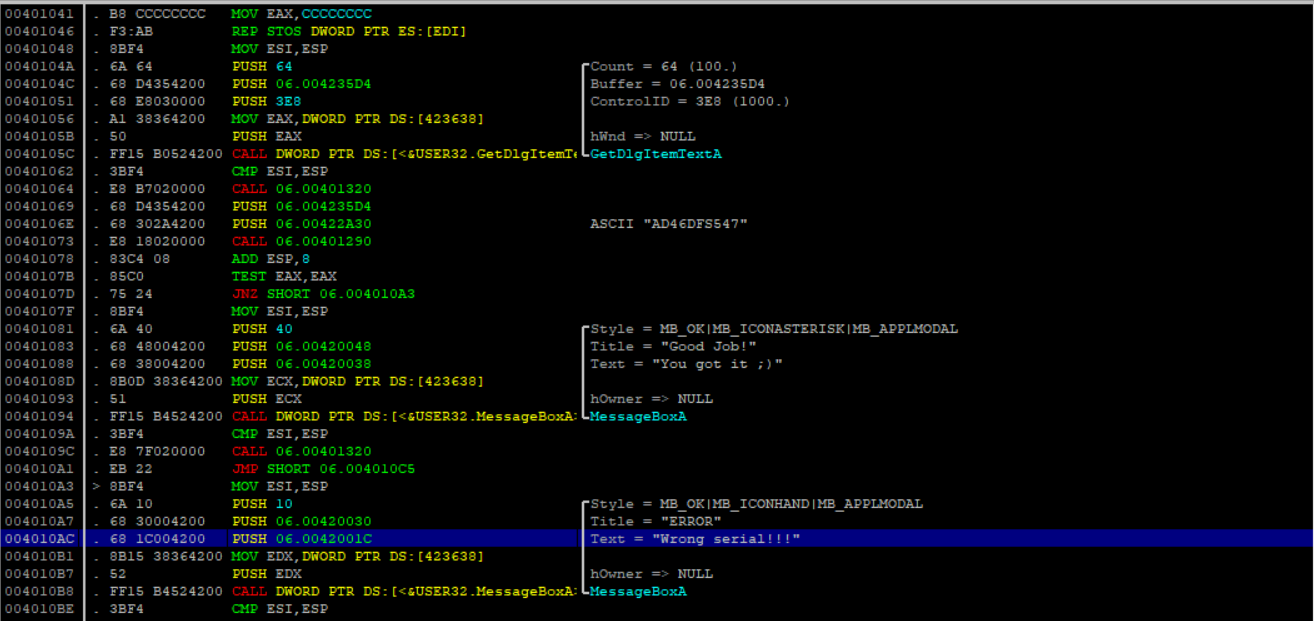
마지막으로 알아볼 구조체는 "_IMAGE_IMPORT_DESCRIPTOR" 입니다. ( 어떤 라이브러리를 import하고있는 지 )
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; // 0 for terminating null import descriptor
DWORD OriginalFirstThunk; // RVA to original unbound IAT (PIMAGE_THUNK_DATA)
} DUMMYUNIONNAME;
DWORD TimeDateStamp; // 0 if not bound,
// -1 if bound, and real date\time stamp
// in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND)
// O.W. date/time stamp of DLL bound to (Old BIND)
DWORD ForwarderChain; // -1 if no forwarders
DWORD Name;
DWORD FirstThunk; // RVA to IAT (if bound this IAT has actual addresses)
} IMAGE_IMPORT_DESCRIPTOR;
_IMAGE_IMPORT_DESCRIPTOR 한 개 모습
< 주요 멤버 >
OriginalFirstThunk: Import Name Table의 주소(RVA) -> 주소 raw로 계산해서 따라가보면 table이 쭉 나오고 다 파싱해서 가져옴
Name: 라이브러리 문자열을 담고 있는 주소(RVA) -> 주소 raw로 계산해서 따라가보면 라이브러리 나옴(null까지 문자 받기)
FirstThunk: Import Address Table의 주소(RVA) -> 잘 모르겠음.. ㅎㅎ
이 부분은 말로만 해서 잘 모르겠어서 같이 따라가면서 확인해보도록 하자.
OriginalFirstThunk값이 0x7990이다. RAW로 바꾸면 0x6d90.
0x6d90으로 가보면
OriginalFirstThunk 따라가기
이렇게 나타나는데 0x00 00 00 00 이 나올때까지 받으면 그게 테이블의 끝이 된다.
Name 부분은 0x7aac 인데 RAW로 바꾸면 0x6eac이다.
Name 따라가기
따라가보면 이름이 나온다.
FirstThunk는 따라가봤는데 이상한게 나와서 잘 머르겠다밍~~~ 위와 같은 방법으로 따라가보면 뭔가 있긴 한데 뭔지 모르겠다.. 아시는 분은 댓글로 알려주세요!!
FirstThunk 따라가기Import Descriptor의 일부 출력 모습
위에서 계속 언급했는데 RVA는 뭐고 RAW는 뭘까?
RVA는 메모리상에서의 주소, RAW는 파일에서의 주소라고 생각하면 편하다. 내가 계속 RAW를 구했던 이유는 메모리에 올라가있는 걸 본 게 아니라 파일형태로 되어있는 상태로 따라가고 있기 때문이다.
나뭇잎책에서 가져온 비례식
RVA( 메모리 상의 주소 ) - VirtualAddress( 메모리 상의 시작주소 ) : 시작으로부터 얼마나 떨어져있는 지
PointerToRawData( 파일에서의 섹션 시작 주소 )를 더해주면 같은 만큼 떨어져있던 친구를 구할 수 있따~ 라고 이해하면 편하다! --> 이렇게 해도 모르겠는 분들을 위한 예제!!! ( 이것도 나뭇잎책 ㅎㅎ )
이 상황에서 RVA가 0x2000이라면?
1. RVA는 Memory에서의 주소기 때문에 0x2000이 속해있는 섹션을 찾습니다.
2. 그럼 0x1000 부터 시작되는 text 섹션이되겠네요. (imagebase 값 무시하고 생각, 여기서 imagebase는 0x1000000)
3. 그럼 0x2000(RVA)-0x1000(메모리에서의 text 섹션 시작주소==VirtualAddress)+0x400(파일에서의 text 섹션 시작주소==PointerToRawData) 하면???
1) 이론적인 불가능성에 대한 정보 보안성(informational security) : 보안을 정량화 하지 않는다. ( 실제 응용에서 쓸모가 없다. )
2) 실질적인 불가능성에 대한 계산 보안성(computational security) : 암호의 세기를 실질적으로 측정
3.1.1 이론적인 보안성: 정보 보안성
암호를 깨는 것이 가능한지 아닌지에 관한 것
ex) 백만년을 들어서 깰 수 있다면 ? 그 암호는 정보적으로 불안전한것.
3.1.2 실용적인 보안성: 계산 보안성
적당한(reasonable) 시간과 적당한 자원( 메모리, 하드웨어, 예산, 에너지 등)안에 깰 수 없으면 안전하다고 간주.
ex) 백만년을 들여서 깰 수 있다고 했을 때 백만년은 적당한 시간이 아니기 때문에 계산 보안성을 갖추고 있는 암호라고 할 수 있다.
- 계산 보안성을 표현
t : 공격자가 수행할 연산 횟수의 한계, 노력의 하계(lower bound; 보안을 깨는 데 필요한 최소한의 연산 횟수)
ε : 한 공격의 성공 확률의 한계 ( 엡실론 )
- (t,ε) 보안이란
: 공격자가 최대 t회의 연산을 수행할 수 있고 그 성공 확률이 ε을 넘지 않을 때의 암호
: 즉, 공격자가 적어도 t번을 연산을 했을 때 성공 확률이 ε라는 것이지 t번을 해서 깰 수 있다는 것이 아님.
3.2 보안성의 정량화
안전하다고 간주되는 어떤 암호가 주어졌을 때 우선 파악해야 할 것은 그 암호가 어느 정도의 공격 노력을 견딜 수 있는지이다. 이를 답하기 위해서 다음 절들을 공부해보쟈.
3.2.1 비트수를 척도로 한 보안성의 측정
- t 보안
: 계산 보안성의 맥락에서, 성공적으로 공략하는 데 적어도 t회 연산이 필요한 암호
: 성공 확률 ε이 1에 가깝다고 가정
- n비트 보안, n비트 안전
: 주어진 보안 개념을 침해하는 데 약 2^n회의 연산이 필요하다
--> 연산 횟수를 알 수 있다면 이진 로그를 취해서 그 암호의 보안 수준(security level)을 알 수 있다.
- 비트 보안성은 암호들의 보안 수준을 비교할 때는 유용, but 실제 비용에 대한 정보를 충분히 주지않는다.
3.2.2 전방위 공격 비용
실질적인 보안 수준을 추정할 때, 병렬성, 메모리, 계산 전 연산, 공격 대상 수 를 반드시 고려해야 한다.
- 병렬성
두 공격이 있을 때 한 공격은 순서 의존적(sequentially dependent) 연산을, 다른 한 공격은 순서 독립적(sequentially independent)이라고 하자. 당연히 병렬 즉 순서 독립적 공격이 더 빠르게 작업을 할 수 있다.
- 메모리
공격의 공간 소비와 관련해서 중요하게 고려할 사항은 1회의 공격 도중 필요한 메모리 참조(lookup) 횟수, 메모리 접근 속도(읽기, 쓰기 속도 다를 수 있음), 접근한 자료의 크기, 접근 패턴(연속된 메모리 주소 접근 또는 임의 메모리 주소 접근, 연속된 메모리 주소 접근이 더 빠름), 메모리 안의 자료 구조 등이다.
- 사전 계산
사전계산 : 공격 시 한 번만 수행한 후 계속 재사용할 수 있는 연산, 공격의 오프라인 단계(offline stage)라고 부르기도 한다.
실제 사례 ) 2G 이동통신 암호화에 대한 한 공격은 2개월의 시간을 들여서 2TB 분량의 참조표를 생성, 그것을 이용하여 2G 암호화를 깨고 비밀 세션 키를 얻는 데는 단 몇 초밖에 걸리지 않았다.
- 공격 대상 수
공격 대상이 많을 수록 공격면(attack surface)도 넓어진다.
ex) n비트 키를 공격 대상으로 삼는다 하면 2^n 만큼의 시도가 필요하겠지? 근데 그 중 M개의 키를 찾는다고 하면 또한 M개를 모두 찾는게 아닌 그중 하나만 찾아도 된다면 M/2^n 이겠지?
정리하자면 대상의 수가 증가하면 공격의 비용과 시간이 감소한다는 것이다.
3.2.3 보안 수준의 선택과 평가
현재 보안 수준을 선택할 때는 흔히 128비트 보안성과 256비트 보안성 중 하나를 선택하게 된다.
64비트나 80비트는 보안성이 충분하지 않기 때문이다.
3.3 보안의 달성
보안 수준을 선택한 후에는 암복호화 방안이 그 수준을 유지하게 하는 것이 중요하다.
암복호화 알고리즘의 보안성에 관한 확신을 가지는 방법에는 아래 두가지가 있다.
1) 수학적 증명에 의존하는 증명 가능 보안성(provable security)
2) 알고리즘을 깨려고 했지만 실패한 사례들을 증거로 삼는 발견법적 보안성(heuristic security)
3.3.1 증명 가능 보안성
: 주어진 암복호화 방안을 깨는 것이 다른 어떤 어려운 문제를 풀기보다 쉽지 않음을 증명한다.
그러한 보안성 증명(security proof)이 있다면 해당 난해 문제가 여전히 어렵다 -> 암호도 어렵다 -> 안전
이런 증명을 환원(reduction)이라고 한다.
1) 수학 문제를 기준으로 한 증명
ex) 소인수분해 문제(factoring problem) - RSA
두 소수의 곱 (n = pq)임이 알려진 어떤 수가 주어졌을 때 그 두 소수를 구하는 것이다. n이 작을 때는 쉽게 풀리지만 n의 비트수가 3000 이상이면 현실적으로 불가능하다고 간주한다.
- RSA
평문을 암호화 할 때 : 평문 P를 커다란 수로 취급해서 C = P^e mod n 을 계산한다. ( e,n :공개 키 )
암호문을 복호화 할 때 : P = C^d mod n ( d :비밀 키 )
-> n을 소인수분해할 수 있으면 RSA 깰 수 있음(공개 키에서 비밀 키를 복원), 비밀 키를 얻으면 n을 소인수분해할 수 있음.
2) 다른 암호학 문제를 기준으로 한 증명
: 대칭 암호에 대한 보안성 증명할 때 쓰임
ex) 완벽한 해시 알고리즘이 있다고 가정을 하고 우리가 만든 암복호화 방안이 해시 기반이라면 해시 알고리즘 보다 약하지 않음을 증명할 수 있다.
장점 : 암복호화 방안을 다 살펴볼 필요가 없이 핵심 알고리즘만 살펴보면 된다. ( 공격 벡터가 줄어 들어 살펴봐야할 곳도 줄어든다. )
3) 함정들
- 수학에서 증명은 '절대적 진리'를 입증하는 것이지만, 암호학에서 증명은 그냥 '상대적 진리'를 보여주는 것일 뿐이다.
- 어떤 암호의 비밀키를 복원하는 것이 소인수분해를 푸는 것만큼 어렵다고 증명했을 때, 공격자가 키 없이 평문을 복원할 수 있다면 키를 복원하는 것이 얼마나 어려운지는 문제가 되지 않는다.
- 종종 어려운 수학 문제가 생각보다 쉽게 풀린다는 점이 밝혀지기도 한다.
- 알고리즘의 보안성 증명이 옳다고 해도, 알고리즘 구현이 약할 수 있다.
3.3.2 발견법적 보안성
- 증명 가능 보안성은 암복호화 방안에 관한 확신을 얻는 데 아주 좋은 수단이지만, 모든 종류의 알고리즘에 적용할 수 있는 것은 아니다. 사실 대부분의 대칭 암호에는 보안성 증명이 존재하지 않는다.
- 증명 가능 보안성 접근 방식을 적용할 수 없는 경우, 어떠한 암호가 안전하다고 믿는 유일한 근거는 수많은 능력있는 사람들이 그것을 깨려고 했지만 실패했다는 점밖에 없다. -> 발견법적 보안성
ex) 암호를 만들어 놓고 세계적으로 유명한 암호해독가 103982명을 불러서 깨보십쇼 했는데 못깨면? 암호가 안전하다고 믿는 것이다.
3.4 키 생성
뭔가를 암호화하려면 키들을 생성해야 한다. 암호학적 보안에서는 비밀 키가 관건이다.
암복호화를 위한 키는 3가지 방식 중 하나로 만들어 내야 한다.
1) 무작위 생성 : PRNG 사용하고, 필요하다면 키 생성 알고리즘 사용 ( 아래 설명들은 무작위생성을 기준으로 함 )
2) 패스워드 기반 생성 : 사용자가 제공한 패스워드를 하나의 키로 변환하는 키 유도 함수( Key derivation function, KDF ) 사용
3) 키 합의 프로토콜 : 둘 이상의 통신 당사자들이 특정한 프로토콜에 따라 메시지들을 교환해서 하나의 공유 키를 확립한다.
3.4.1 대칭 키 생성
대칭 키 : 두 당사자가 공유하는 비밀 키, 생성하기가 가장 쉬움
: 흔히 키의 길이 == 보안 수준
: 암호학적 PRNG를 이용해서 n 비트 생성해서 그거를 쓰면 됨.
3.4.2 비대칭 키 생성
비대칭 키는 대칭 키 보다 생성하기 어렵다!!
비대칭 키를 생성하기 위해서는 의사난수 비트들을 종잣값으로 사용해서 키 생성 알고리즘(key-generation algorithm)을 실행해야 한다.
- 키 생성 알고리즘
: RSA를 위한 키 생성 알고리즘은 난수 두 개를 생성해서 n=pq 를 산출 하고 난수이면서 소수인 p,q를 얻기 위해서 소수판별 알고리즘도 필요함.
대부분의 사람들은 11010110이 더 무작위해 보인다고 한다. 하지만 확률로 따져보았을 때, 둘은 1/(2^8)의 확률로 동일하게 생성된다. 여기서 사람들이 무작위성(randomness)을 식별할 때 저지르는 두 가지 오류를 확인할 수 있다.
1) 비무작위성(non-randomness)을 무작위성으로 오해 : 단지 무작위해보인다는 이유로 무작위하게 생성되었다고 생각하는 실수
2) 무작위성을 비무작위성으로 오해 : 어떠한 패턴을 보고 그런 패턴이 발생한 이유가 있을 것이라고 생각하는 실수
** 보안을 위해서 무작위해 보이는 것과 실제로 무작위한 것을 구별하는 것은 굉장히 중요!!
2.2 확률분포로서의 무작위성
- 확률분포
: 주어진 과정의 무작위성에 관해 알아야 할 모든 정보를 제공한다.
: 무작위 과정의 모든 가능한 결과에 부여된 확률(probability)을 나열한 것이다.
- 균등분포 ( uniform distribution : 또는 고른 분포 )
: 모든 결과의 발생 가능성이 같다.
ex) 128비트 키를 무작위로 고르게 선택한다면 1/(2^128) 만큼 의 확률로 선택
- 비균등분포 ( non-uniform distribution )
: 확률들이 모두 같지는 않은 분포
ex) 동전 던지기에서 앞면과 뒷면이 나올 확률이 다르다고 가정할 때.
-> 이러한 동전을 가리켜 ' 편향되었다(biased) ' 라고 한다.
2.3 엔트로피 : 불확실성의 측도
- 엔트로피
: 시스템에 존재하는 무질서의 측도(measure)
: 어떤 무작위 과정이 의외의 결과를 내는 경우가 얼마나 많은지를 나타내는 값
: 정보를 비트들의 개수로 표현할 수 있게 이진 로그를 사용
: 수식에서 음의 합을 사용하는 이유 : log(1/2) 면 (물론 이진로그) 음의 값이 나오기 때문에 엔트로피를 음수가 아닌 값으로 맞춰주기 위해서 음의 합 사용
: 엔트로피는 확률분포가 균등분포일 때 최대 ( 균등분포는 모든 확률이 같기 때문에 불확실성이 최대 )
-> 만약 5가지의 선택사항이 있을 때
a) 모든 확률은 1/5로 같음
b) 1/25, 18/25, 2/25, 3/25, 1/25 각각 이런 확률
그러면 a)는 모든 확률이 같기 때문에 무엇이 선택될 지 예측 불가능
b)는 2번이 선택될 것이라 예측 가능
** 정리를 해보면
엔트로피가 높다??? 예측이 어렵고, 랜덤하다.
2.4 난수 발생기(RNG)와 의사난수 발생기(PRNG)
암호 시스템은 무작위성을 얻기 위해 다음과 같은 구성요소를 갖추어야 한다.
1) 불확실성의 원천 또는 엔트로피원(source of entropy) : 난수 발생기 ( random number generator, RNG )가 담당
2) 엔트로피원으로부터 고품질 무작위 비트를 산출하는 암복호화 알고리즘 : 의사난수 발생기 ( pseudorandom number generators, PRNG )가 담당
- RNG : 디지털 시스템 안에서 아날로그 세계의 엔트로피를 이용해서 예측 불가능한 비트들을 산출하는 소프트웨어 또는 하드웨어 구성요소 ( ex) 온도, 음향적 잡음, 공기의 난류, 정전기, 시스템에 부착된 sensor, 입출력장치, 네트워크나 디스크활동, 시스템 로그, 실행중인 프로세스들, 키 입력이나 마우스 이동 등 )
-> 좋은 엔트로피원일 수 있지만, 공격자의 조작과 악용에 취약, 난수 비트들을 생성하는 속도 느림
- PRNG: 적은 수의 진정한 난수 비트들로부터 다수의 인위적인 난수 비트들을 신뢰성 있게 산출
RNG vs PRNG
느리다 빠르다 (비교적)
비결정론적 결정론적
엔트로피가 높다는 보장 X 최고의 엔트로피 보장
** 결정론적 : 예측 그대로 동작하는 알고리즘, 어떤 특정 입력이 들어오면 언제나 똑같은 과정을 거쳐 언제나 똑같은 결과를 내놓는다.
과정 도식화한 것
2.4.1 PRNG의 작동 방식
주기적으로 RNG로부터 받은 난수 비트들을 이용해서 큰 메모리 버퍼(entropy pool)의 내용을 갱신.
엔트로피 풀이 PRNG의 엔트로피원이다.
의사난수 비트열을 생성하기 위해 DRBG( Deterministic random bit generator, 결정론적 난수 비트 발생기 ) 알고리즘 실행. DRBG는 같은 입력을 넣으면 같은 출력이 나옴 -> 같은 입력을 두 번 제공하지 말아야 한다.
작동과정에서 PRNG는 다음 세 가지 연산 수행
1) init() : 엔트로피 풀, PRNG 내부 상태 초기화
2) refresh(R) : 어떤 자료 R( RNG 에서 얻은 자료 ) 을 이용해서 엔트로피 풀 갱신 -> 임의의 통계적 편향 제거
3) next(N) : N개의 의사난수 비트 생성 후 엔트로피 풀 갱신
2.4.2 보안 관련 문제
PRNG에 요구되는 몇 가지 고수준 사항
1) 역추적 저항성 ( backtracking resistance; 순방향 비밀성 ) : 이전에 생성된 비트들을 절대로 다시 생성할 수 없어야 한다. -> refresh, next 연산에서 내부 상태를 갱신할 때 수행되는 변환들이 비가역적이어야 한다.
2) 예측 저항성 ( prediction resistance; 역방향 비밀성 ) : 이후의 비트들을 예측하는 것이 불가능해야 한다. -> 공격자가 알지 못하고 추측하기 힘든 R 값으로 refresh를 호출해야한다.
2.4.4 암호학적 PRNG와 비암호학적 PRNG
비암호학 PRNG : 응용 프로그램에서 균등 분포 무작위 비트열을 산출하도록 설계된 것들, 안전하지 않다.
암호 PRNG : 잘 분포된 비트들을 산출하는 데 쓰이는 바탕 연산들의 강도에 신경 쓰기 때문에 예측 불가능.
하지만 여러 시스템에 쓰이는 것은 대부분 비암호 PRNG임. ex) 메르센 트위스터
- 메르센 트위스터 ( Mersenne Twister, MT )
: PHP, 파이썬, R, Ruby를 비롯한 여러 시스템에 쓰이는 비암호 PRNG이다.
: 통계적 편향이 없는 균등분포 무작위 비트열을 생성하지만 예측 가능하다 -> 내부 작동 방식을 살펴보면 죄다 xor 을 통해서만 상호작용하기 때문이다.
* 비트들의 XOR 결합을 선형결합이라고 부른다. -> 선형결합은 예측이 가능하다. ( AND 결합은 비선형결합 )
2.5 실제로 쓰이는 PRNG들
데스크톱과 노트북, 네트워크 라우터나 센톱박스 같은 내장 시스템을 비롯한 대부분의 플랫폼은 운영체제 차원에서 암호학적 PRNG를 제공.
가장 널리 쓰이는 PRNG는
1) 여러 Unix 기반 시스템이 제공하는 것
2) Windows가 제공하는 것
3) 인텔 마이크로프로세서에 쓰이는 하드웨어 기반 PRNG 이다.
2.5.1 Unix 기반 시스템에서 무작위 비트 생성
장치파일 /dev/urandom 은 암호 PRNG를 제공하는 사용자 영역 인터페이스이다.
신뢰성 있는 무작위 비트들을 얻을 때 이 장치 파일을 생성한다.
리눅스가 사용하는 PRNG는 drivers/char/random.c 에 정의되어있고 SHA-1 해시 함수를 이용하여 원본 엔트로피 비트 -> 신뢰성 있는 의사난수 비트를 만듦.
/dev/urandom은 비차단 ( non-blocking ) 풀 , /dev/random은 차단 풀을 사용
** /dev/urandom 과 /dev/random은 무슨 차이일까?
/dev/random은 엔트로피 양을 추정하여 엔트로피 수준이 낮으면 비트들을 돌려주지 않는다. 이것이 좋은 방식인 것 같지만 신뢰성이 낮기로 악명이 높고, 공격자가 그것을 속여 넘길 수 있다고 한다.
그리고 추정된 엔트로피를 상당히 빨리 소진하여, 엔트로피가 높아지길 기다리느라 응용프로그램이 느려진다.(DOS 가능)
이래서 /dev/random은 별로라고 한다!!
2.5.2 Windows의 CryptGenRandom() 함수
예전 버전의 Windows 에서는 운영체제의 PRNG에 대한 사용자 영역 인터페이스로 CryptGenRandom() 함수가 쓰였다.
최근 버전의 Windows 에서는 Cryptography API: Next Generation(CNG) 라는 API의 BCryptGenRandom()함수가 쓰인다.
윈도우 PRNG는 커널 모드 드라이버 cng.sys(전에는 ksecdd.sys) 에서 엔트로피를 가져오는데 느슨하게 말하면 포르투나에 기초한다. (난수를 얻는 과정 꽤나 복잡)
CryptGenRandom()- 핸들을 이용하여 암복호화 문맥 얻어야함 -> 이 과정에서 잘못될 기회가 늘어남
BCryptGenRandom() - 핸들 없이 가능!
2.5.3 하드웨어 기반 PRNG: 인텔 마이크로프로세서의 RDRAND 명령
응용 프로그램은 RDRAND라는 어셈블리 명령을 통해 인텔의 이 PRNG에 접근.
운영체제와는 독립적인 인터페이스 제공, 이론상 소프트웨어 PRNG보다 빠름
2.6 문제 발생 요인들
다음 4가지의 예시를 보쟈!
2.6.1 불충분한 엔트로피원
- 넷스케이프 브라우저 SSL 구현은 128 비트 PRNG 종잣값을 계산할 때
global variable seed;
RNG_CREATEContext()
(seconds, microseconds) = 하루 중 시간
pid = 프로세스 id; ppid = 부모 프로세스 id; /* 각 15 비트 */
a = mklcpr(microseconds);
b = mklcpr(pid + seconds + (ppid << 12));
seed = MD5(a, b);
mklcpr(x)
return ((0xDEECE66D * x + 0x2BBB62DC) >> 1);
MD5()
이 의사코드에 따라 계산을 하는데
seconds 를 알아버리면 microseconds의 seconds/10^6 이므로 이 때 엔트로피가 log(10^6) 즉 약 20비트.. 여기서 큰 빵꾸가 나기 때문에 엔트로피가 128비트가 안된다.. 그래서 문제 발생함.
또한 b를 구하는 과정에서 ppid 를 왼쪽으로 12비트 shift 해서 3비트가 겹쳐버려서 여기서의 엔트로피 15(pid)+12(ppid) 이므로 3비트 빵꾸남 원래 15+15 여야 하는 데 그래서 문제 발생!!
2.6.2 시동 시점의 엔트로피 부족
시동(booting) 도중 아직 엔트로피가 충분히 수집되지 않은 시점에서 엔트로피를 계산하는 장치가 많다는 것을 조사를 통해 얻음 -> 엔트로피가 충분치 않다 보니서로 다른 시스템의 PRNG들이 동일한 기본 엔트로피원으로부터 동일한 난수비트들을 생성 -> 동일 키 생성됨
prng.seed(종잣값)
p = prng.generate_random_prime()
q = prng.generate_random_prime()
n = p*q
/* 결과적으로 n이 같아지는 시스템 */
생성 도중에 추가적인 엔트로피 주입되는 키 생성 방안을 의사코드로 나타내면 아래와 같다.
prng.seed(종잣값)
p = prng.generate_random_prime()
prng.add_entropy()
q = prng.generate_random_prime()
n = p*q
이 시스템에서 p가 같다 하더라도 추가적인 엔트로피 주입으로 인해 n은 달라진다. 하지만 n과 n' 의 최대공약수를 계산하면 공통인 소인수인 p를 알아낼 수 있기에 문제가 생긴다. (문제 : 개인키를 알아낼 수 있음)
2.6.3 비암호 PRNG
앞서 말했듯이 비암호 PRNG는 안전하지 않다.
예를 들어 위키백과를 비롯한 여러 위키 사이트는 Media Wiki를 사용한다. Media Wiki는 무작위성을 활용해서 보안 토큰이나 임시 패스워드를 생성했으며 이때 mt_rand() 함수를 이용하여 생성했다. mt_rand()는 메르센 트위스터이다.. 예측 가능하단 소리! 그래서 안전하지 않다!!
2.6.4 무작위성은 강하지만 표본 추출에 문제가 있는 사례
Cryptocat 이라는 채팅 프로그램은 보안 통신을 제공하도록 설계되었다.
0~9 의 숫자들을 고르게 분포하려고 했는데 0부터 255까지의 모든 수를 10으로 나눈 나머지에서는 0~9가 고르게 분포되지 않는다. ( 1 byte = 8 bits 라서 0부터 255 )
그래서 이 개발자들은 다음과 같은 방법을 사용했다.
Cryptocat.random = function() {
var x,o ='';
while(o.length < 16) {
x = state.getBytes(1);
if(x[0] <=250)
o += x[0] % 10;
}
}
10의 특정 배수인 250을 조건으로 해서 그 미만의 수에서만 10으로 나눈 나머지를 취하고 그외는 버리는 방법을 사용했다. 근데 250을 10으로 나누면 0이라는 수가 한번 더 나오게 되서 균등하지 못하게 된다. 그래서 엔트로피가 낮아진다.
암호의 주된 구성요소 = 치환 ( permutation ) , 운영모드 ( mode of operation; 운용 방식 )
- 치환 : 주어진 한 항목을 변환하는 함수 ( 조건 : 고유한 역원 존재해야 함 )
- 운영모드 : 치환을 이용해서 임의의 길이의 메시지를 처리하는 데 쓰이는 알고리즘
1.3.1 치환
고전암호는 대입 ( substitution ; 대체 )을 수행. -> substitution은 한 문자를 다른 문자로 바꿔서 confusion의 목적을 둠
암호를 위한 대입은 반드시 치환이어야 한다. -> 각 글자에 정확히 하나의 역원이 존재해야 한다.
"안전한 치환 ( secure permutation )" -> permutation은 문장 순서를 바꿔서 diffusion의 목적을 둠
1) 치환은 반드시 키로 결정되어야 함.
2) 키가 다르면 치환도 다름.
3) 무작위 해 보여야 함.
1.3.2 운영 모드
만약 평문에 BANANA와 같이 특정 패턴이 있어버리면 암호문에도 이것이 드러나게 된다.
운영모드를 사용하여 중복 글자 패턴이 드러나는 문제를 완화한다.
ex) ECB, CBC, CFB, OFB, CTR
1.4 OTP ( One Time Pad )
가장 안전한 암호 : 키가 엄청나게 길고 한번 쓰고 버림
bitwise XOR 연산을 통해서 암호화, 복호화를 한다.
키는 평문의 길이와 같으며 키를 위한 또 다른 공간이 존재해야 해서 활용하기 불편. ( 공간상의 낭비 )
완벽한 보안성을 달성하려면 키가 평문보다 짧아서는 안된다.
1.5 암호의 보안성
어떠한 시스템이 안전하다? 보안개념(security notion) 을 서술해야 함.
보안 개념은 보안목표 - 공격 모형 형태로 나타냄.
1.5.1 공격 모형
- 케르크호프스의 원리 ( Kerckhoffs's principle ) : 한 암호의 보안성은 오직 키의 비밀성에만 의존해야 한다. -> 적이 암호시스템 훔쳐 가도 문제가 되어서는 안된다. --> 모든 모형이 공통적으로 두는 가정
1) 공격 모형 - 블랙박스 모형
- COA ( ciphertext-only attackers ) : 공격자가 불리한 공격 , 암호문만 알뿐 해당 평문 알지 못함. 암호화 질의 X, 복호화 질의 X
- KPA ( known-plaintext attackers ) : 암호문에 대응하는 일부 평문을 알 수 있다, 암호문과 평문과의 관계로부터 키와 전체 평문을 추정하여 해독, 암호화 질의 X, 복호화 질의 X
- CPA ( chosen-plaintext attackers ) : 암호화 질의 O
- CCA ( chosen-ciphertext attackers ) : 암호화 질의 O, 복호화 질의 O
2) 공격 모형 - 그레이박스 모형
: 암호의 구현( implementation) 에 접근 가능
: 시스템에 물리적으로 접근해서 알고리즘 내부를 건드릴 수 있다.
- 부채널 공격(side-channel attack) : 공격자는 아날로그 특성을 관찰, 측정만 하여 구현의 무결성을 훼손 X
- 침습적 공격(invasive attack) : 암호 구현을 강하게 공격 , 구현의 무결성을 훼손할 수도 있다.
+ 공격 모형에 화이트박스 모형도 있음ㅎㅎ
1.5.2 보안 목표
- 비구별성(indistinguishability, IND) : 암호문은 무작위 문자열과 구분할 수 없어야 안전하다.
- 비가소성(non-malleability, NM) : 어떤 평문에 대한 암호문을 안다고 해서, 다른 평문에 대한 암호문을 얻을 수 없어야 안전하다.
1.5.3 보안 개념
- 의미론적 보안 IND-CPA
목적 : 키의 비밀이 유지되는 한 공격자가 암호문으로부터 평문에 관해 그 어떤 정보도 알아내지 못해야한다.
-> 이를 위해 무작위 암호화 ( randomized encryption ) 사용 , 이때 DRBG(결정론적 무작위 비트 발생기) 사용
** 보안 개념들의 함의 관계 -> 교수님께 여쭤보기 ㅜㅜ
1.6 비대칭 암호화
- 키가 2개 사용됨
- 암호화할 때는 receiver의 공개키를 사용
- 복호화할 때는 receiver의 개인키를 사용
- 공개키를 가지고 있는 사람이면 누구나 암호화 질의를 수행할 수 있다. -> 기본 공격 모형 : CPA
* 하이브리드 암호시스템 ( 대칭 암호화와 비대칭 암호화의 조합 )
-> 대칭 암호화의 장점 : 빠르다.
-> 비대칭 암호화의 장점 : 키를 안 주고 받아도 된다.
하이브리드 암호시스템의 암호화 과정
1.7 암 · 복호화 이외의 암호의 용도
1) 인증 암호화 ( Authenticated encryption, AE )
: 암호화하면 인증값 T 을 같이 돌려준다.
- AEAD ( Authenticated encryption with associated data )
: 흔히 평문 헤더와 암호화된 페이로드 ex) 네트워크 패킷들을 전송하기 위해서 목적지 주소는 평문이어야한다.
2) 형태 보존 암호화 ( format - preserving encryption, FPE )
: 평문과 같은 형태의 암호문을 생성!! ex) IP주소를 IP주소로 암호화, ZIP 코드( 미국의 우편번호 )를 ZIP코드로 암호화
3) 완전 준동형 암호화 ( fully homomorphic encryption, FHE )
: 암호문을 복호화하지 않고 또 다른 암호문으로 바꿈
: 느리다!!
4) 검색 기능 암호화 ( searchable encryption )
: 암호화된 데이터베이스에 대한 검색 가능
: 검색 질의 자체를 암호화해서 검색어 유출 방지
ex) 내가 클라우드에 고객들의 정보를 저장한다고 했을 때, '김포렌' 라는 고객의 정보를 알고 싶어서 쿼리를 날리면 검색 기능 암호화를 지원하면 '김포렌'를 암호화해서 암호화된 데이터베이스에 접근하여 정보를 나에게 다시 보내주고 우리는 그것을 복호화 해서 보면 된다. -> 마음 놓고 클라우드 서비스를 이용할 수 있다. ( 안전하기 때문 )
5) 조율 가능 암호화 ( tweakable encryption, TE )
: 조율값(tweak)이라고 부르는 추가적인 매개변수 있다.
: 주된 용도는 디스크 암호화 -> 저장 장치의 내용을 암호화 하는 데 쓰임. ( 무작위 암호화 같은 경우는 자료의 길이가 길어지기 때문에 사용할 수 없음, 암호화때문에 길이가 길어지면,,, 납득 불가! )
: 암호화되는 자료의 위치( 디스크 내의 섹터 번호, 블록 색인 )에 의존하는 조율값 활용






































































 m20190501.zip
m20190501.zip











